

코딩복습장
LSTM을 이용한 spam 메일 분류하기 ( Pytorch ) 본문
이번에는 lstm을 사용해서 스팸메일을 분류해보려고 한다.
데이터의 정보를 불러오자

dataframe의 shape는 (5572, 5)라는 것을 알 수 있다.
여기서 Unnamed: 2, Unnamed: 3, Unnamed: 4 는 모두 삭제해야될 column들이다.
v1의 ham은 스펨메일이 아님 spam은 스팸메일이라는 뜻이다.
우선 lstm에 데이터를 넣기 전에 data를 분류해야 된다.
나는 train_data, val_data, test_data(훈련 데이터, 검증 데이터, 테스트 데이터) 이렇게 3가지로 데이터를 나눌 것이다.
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer,BertTokenizer
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
data = data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1)
train_df = data.loc[:4000, :].reset_index()
val_df = data.loc[4000:5000, :].reset_index()
test_df = data.loc[5000:, :].reset_index()
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')코드의 마지막 줄에는 tokenizer가 보인다.
나는 NLP preprocessing에 Transformers의 BertTokenizer를 썼다.
NLP preprocessing을 크게
토큰 -> 정제/추출 -> 정수 인코딩으로 볼 수 있는데
BertTokenizer를 쓸 경우 정수 인코딩까지 한 값으로 바로 도달할 수 있어 편리하다.
이 다음 나는 pytorch를 사용해서 LSTM_net을 구현하였다.
class LSTM_net(nn.Module):
def __init__(self, hidden_size, output_size, emb_dim, size_vocab, num_layer):
super(LSTM_net, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layer = num_layer
self.emb_dim = emb_dim
self.size_vocab = size_vocab
self.embed = nn.Embedding(size_vocab, emb_dim)
self.lstm = nn.LSTM(input_size=emb_dim, hidden_size=hidden_size, num_layers=num_layer, dropout=0.3, bidirectional=True)
self.fclayer = nn.Linear(hidden_size, hidden_size)
self.output_layer = nn.Linear(hidden_size, output_size)
def forward(self, x):
scaler = 2 if self.lstm.bidirectional==True else 1
emb = self.embed(x)
lstm, (h, c) = self.lstm(emb.transpose(1, 0))
h = h[-1]
h = self.fclayer(h).relu()
predict = self.output_layer(h)
return predict
코드의 흐름은 다음과 같다.
1. initialize함수로 하이퍼 파라미터를 지정해주고 layer로 쓸 함수를 만들어준다.
2. forward함수로 만든 함수들을 적용시켜준다.
-1. embedding적용 (word2vec을 emb_dim으로 설정해준다.)
-2. lstm적용, 반환되는 값 -> 결과값, (hidden state, cell state) - 결과값과 hidden state는 activation을 적용한 것을
제외하면 값이 같기 때문에 나는 hidden state를 다음 layer로 가져왔다.
(과적합을 방지하기 위해 dropout을 0.3으로 설정해주었다.)
emb.transpose를 써준 이유는 두 layer에서 input으로 받는 데이터의 차원 순서가 다르기 때문이다.
*emb[batch_size, sequence_length, emb_dim]인 반면 lstm[sequence_length, batch_size, emb_dim]이다.
-3. 마지막 값을 가져와야 전체 input데이터의 가중치를 포함하고 있기 때문에hidden state의 마지막값인h[-1]을 가져왔다.
3. fully connected layer를 두번 통과 시켜준 후 값을 반환해주었다. (이 문제는 이진분류 문제이기 때문에 output_size를
2로 설정해주었다.)
model의 구조를 간단하게 살펴보면 다음과 같다.
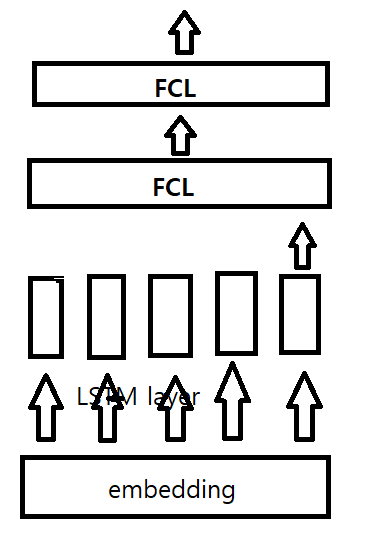
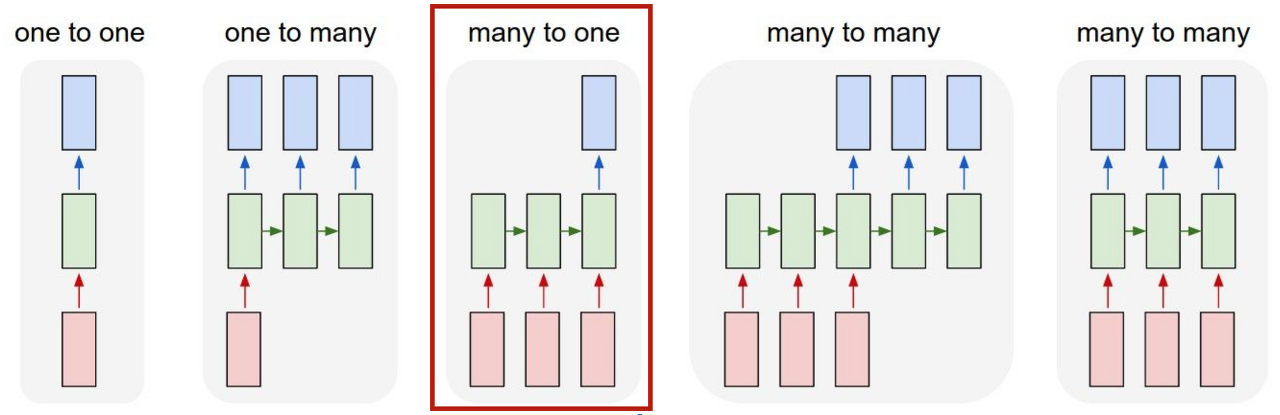
나는 여기서 모든 input의 정보를 담고 있는 output을 써야되기 때문에 many-to-one 구조를 사용하였다.
embedding을 통과하기 전 input인 x의 shape는 [batch_size, sequence_length] 이다.
embedding을 통과한 후는 word2vec이 추가되어서 shape가 [batch_size, sequence_length, embedding_dim]으로 변한다.
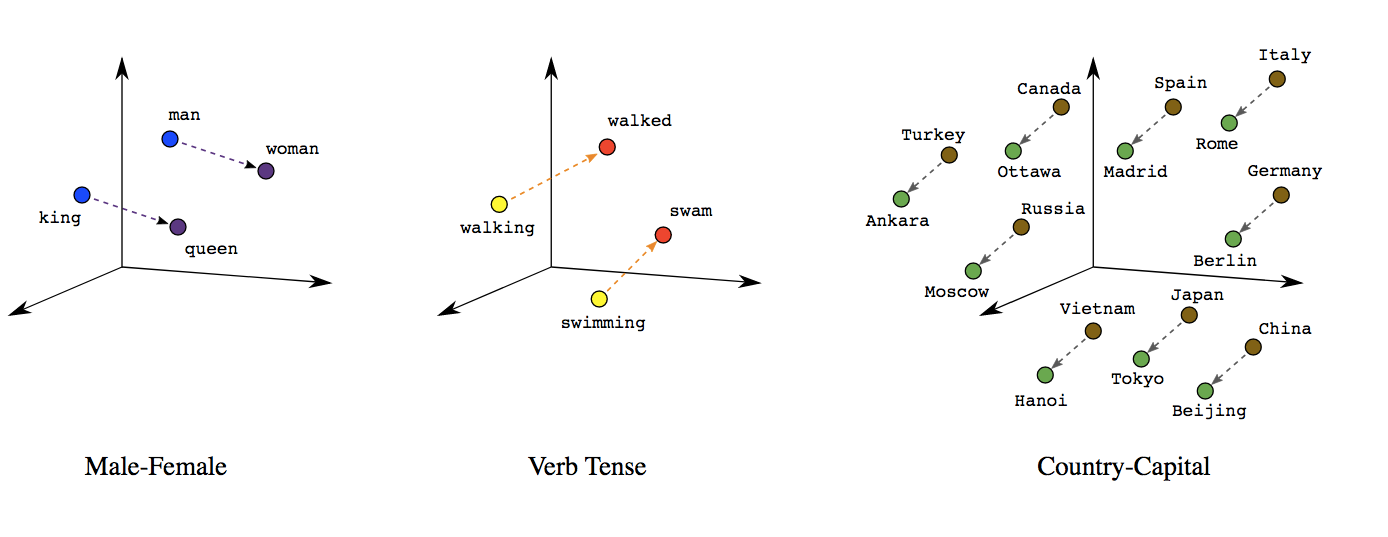
이런 식으로 word2vec가 추가가 되고 embedding_dim에서는 해당 단어의 vector가 저장이 된다.
각각의 단어는 비슷한 단어끼리 가깝게 위치된다.
class myDataset(Dataset):
def __init__(self, df, tokenizer) -> None:
super(myDataset, self).__init__()
self.df = df
self.tokenizer = tokenizer
def __len__(self):
return len(self.df)
def __getitem__(self, index):
data = self.df.loc[index, 'v2']
target = self.df.loc[index, 'v1']
data = tokenizer(data, max_length=100, padding='max_length', truncation=True)['input_ids'] # 토큰화 끝
if target == 'spam':
label = 1
elif target == 'ham':
label = 0
return torch.IntTensor(data), label
train_dataset = myDataset(train_df, tokenizer)
val_dataset = myDataset(val_df, tokenizer)
test_dataset = myDataset(test_df, tokenizer)
batch_size = 100
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size)
for i in train_dataset:
print(i)
break
for i in train_dataloader:
print()
break이제 myDataset class를 이용해서 데이터를 가공해보자.
train_data를 4000개
val_data를 1000개
test_data를 나머지로 하였다.
이전에 설정했던 Bert tokenizer를 통하여 데이터로 들어온 문장을 토큰화 -> 정수화까지 시켜주었다. 그리고 문장이
batch_size만큼씩 한번에 들어가기 때문에 문장의 길이를 맞춰야 한다.
따라서 zero padding을 사용해 문장의 길이를 맞춰주었다.
그리고 조건문을 통하여 target data를 label encoding하였다.
이렇게 preprocessing된 데이터들은 DataLoader를 통해 batch_size만큼씩 불러준다. (train data는 섞어주었다.)
자! 이렇게 데이터를 모두 preprocessing시켜주었기 때문에 이제는 모델을 사용해볼 차례이다.
lstm_net = LSTM_net(hidden_size=64, output_size=2, emb_dim=64, size_vocab=50000, num_layer=1)
optimizer = torch.optim.Adam(lstm_net.parameters(), lr=0.01)이전에 만들었던 LSTM을 불러주고 hyperparameter도 전부 설정해준다.
나는 단어의 개수를 50000개로 설정해주었고 word2vec의 차원을 64로 설정해주었다.
이제 Main을 짜보자
from tqdm import tqdm
from torch.nn import CrossEntropyLoss
lf = CrossEntropyLoss()
for epoch in range(10):
print('Epoch', epoch)
epoch_loss = 0
train_correct = 0
with tqdm(train_dataloader, unit='batch') as tepoch:
for x, y in tepoch:
optimizer.zero_grad()
output= lstm_net(x)
pred_label = torch.argmax(output, dim=-1)
train_correct += sum(pred_label==y)
loss = lf(output, y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(train_correct)
print("train loss", epoch_loss/len(train_dataloader))
print("train acc", train_correct/len(train_dataset))
lstm_net.eval()
val_loss = 0
val_correct = 0
with torch.no_grad():
for x, y in val_dataloader:
output= lstm_net(x)
loss = lf(output, y)
pred_label = torch.argmax(output, dim=-1)
val_correct += sum(pred_label == y)
val_loss += loss.item()
print("val loss", val_loss/len(val_dataloader))
print("val acc", val_correct/len(val_dataset))얼마나 맞았는지는 train_correct, val_correct로 나타내주었다.
실행결과는 다음과 같다.
Epoch 0
100%|██████████| 41/41 [00:22<00:00, 1.86batch/s]
tensor(3536)
train loss 0.25881326268994953
train acc tensor(0.8838)
val loss 0.09740570382299749
val acc tensor(0.9610)
Epoch 1
100%|██████████| 41/41 [00:31<00:00, 1.30batch/s]
tensor(3935)
train loss 0.058821330948664645
train acc tensor(0.9835)
val loss 0.06053824629634619
val acc tensor(0.9800)
Epoch 2
100%|██████████| 41/41 [00:15<00:00, 2.67batch/s]
tensor(3987)
train loss 0.014283237875532926
train acc tensor(0.9965)
val loss 0.06042950257489627
val acc tensor(0.9800)
Epoch 3
100%|██████████| 41/41 [00:13<00:00, 2.95batch/s]
tensor(3997)
train loss 0.00434395532842822
train acc tensor(0.9990)
val loss 0.07543893805466889
val acc tensor(0.9810)
Epoch 4
100%|██████████| 41/41 [00:13<00:00, 2.98batch/s]
tensor(3999)
train loss 0.0017031231968425479
train acc tensor(0.9995)
val loss 0.12170593509228472
val acc tensor(0.9790)
Epoch 5
100%|██████████| 41/41 [00:14<00:00, 2.91batch/s]
tensor(4000)
train loss 0.0007232202687213785
train acc tensor(0.9998)
val loss 0.08037464214263226
val acc tensor(0.9830)
Epoch 6
100%|██████████| 41/41 [00:13<00:00, 3.08batch/s]
tensor(4001)
train loss 9.036982554589929e-05
train acc tensor(1.)
val loss 0.09093556431409153
val acc tensor(0.9820)
Epoch 7
100%|██████████| 41/41 [00:13<00:00, 3.09batch/s]
tensor(4001)
train loss 2.270830697309465e-05
train acc tensor(1.)
val loss 0.0939321905712673
val acc tensor(0.9820)
Epoch 8
100%|██████████| 41/41 [00:11<00:00, 3.44batch/s]
tensor(4001)
train loss 1.668396373865906e-05
train acc tensor(1.)
val loss 0.09637186011635053
val acc tensor(0.9830)
Epoch 9
100%|██████████| 41/41 [00:12<00:00, 3.22batch/s]
tensor(4001)
train loss 1.2985102069628405e-05
train acc tensor(1.)
val loss 0.0984727635090456
val acc tensor(0.9840)내가 학습률을 0.1로 설정해놓았기 때문에 정확도 값이 들쭉날쭉한 것 같다.
하지만 전반적으로 spam메일을 잘 분류하는 모습이다.
이제 모델을 학습시켰으니 test시켜볼 차례이다.
lstm_net.eval()
test_loss = 0
test_correct = 0
with torch.no_grad():
for x, y in test_dataloader:
output= lstm_net(x)
loss = lf(output, y)
pred_label = torch.argmax(output, dim=-1)
test_correct += sum(pred_label == y)
test_loss += loss.item()
print("test loss", test_loss/len(test_dataloader))
print("test acc", test_correct/len(test_dataset))test loss 0.05955511802494584
test acc tensor(0.9948)결과가 아주 잘나온 모습이다!
자 이상으로 spam메일 분류하기 글을 마치겠다!!

읽어주셔서 감사합니다 ~!!
'딥러닝' 카테고리의 다른 글
| Dropout, Batch Normalization (0) | 2025.04.11 |
|---|---|
| Underfitting/Overfitting (0) | 2025.04.10 |
| CrossEntropy 와 Logistic Regression (0) | 2024.04.01 |


